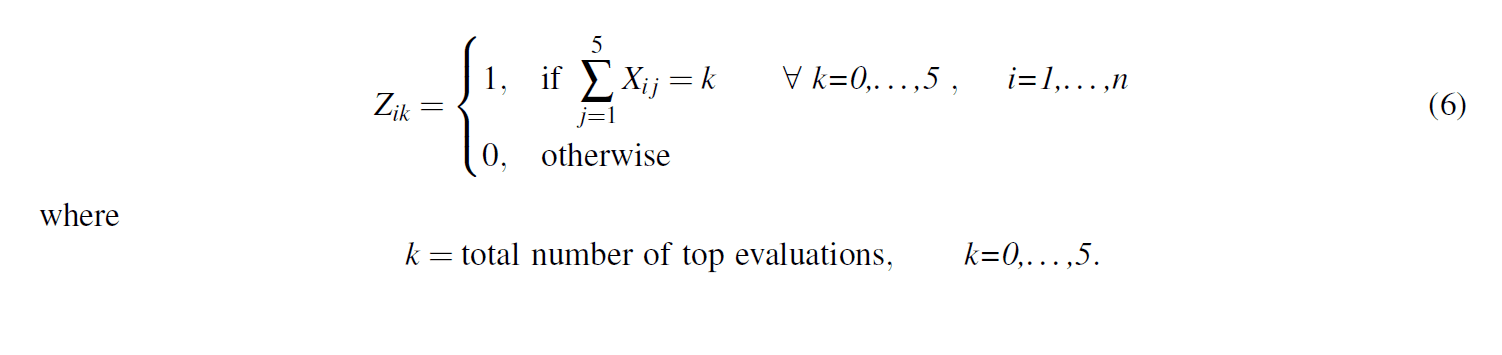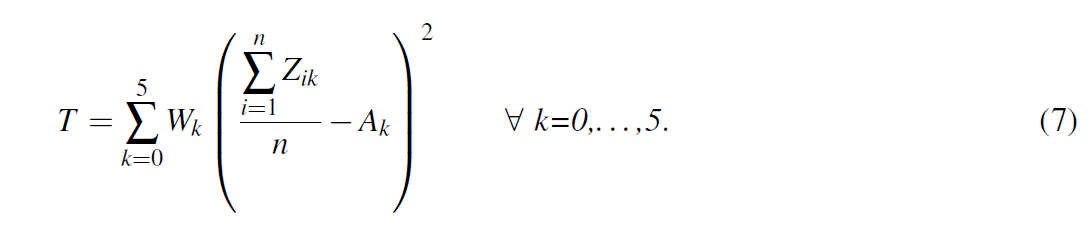by Lee Alan Evans, Ki-Hwan G. Bae, and Arnab Roy (University of Louisville)
As presented at the 2017 Winter Simulation Conference
A discrete event simulation model is developed to represent a forced distribution performance appraisal system, incorporating the structure, system dynamics, and human behavior associated with such systems. The aim of this study is to analyze human behavior and explore a method for model validation that captures the role of subordinate seniority in the evaluation process. This study includes simulation experiments that map black-box functions representing human behavior to simulation outputs. The effectiveness of each behavior function is based on a multi-objective response function that is a sum of squared error function measuring the difference between model outputs and historical data. The results of the experiments demonstrate the utility of applying simulation optimization techniques to the model validation phase of simulation system design.
Background
The United States Army used a variety of techniques to decrease the number of active duty Army personnel from over 566,000 in 2010 to below 470,000 in 2016. These techniques included involuntary separation boards, early retirement boards, decreased accessions, decreased reenlistment opportunities, and decreased promotion rates. Central to each of these force shaping mechanisms, with the exception of decreased accessions, was the analysis of performance appraisals.
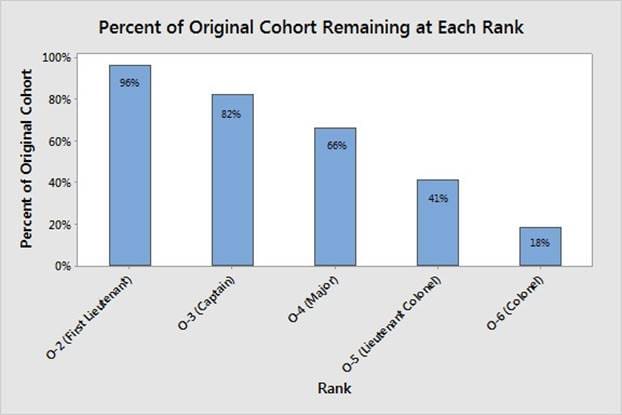
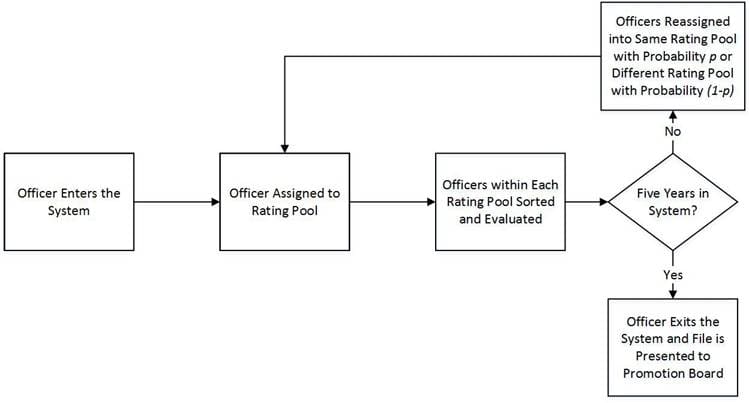
Performance appraisals are of significant importance in the officer ranks due to the Defense Officer Personnel Management Act of 1980 (DOPMA). This act, passed by Congress on December 12, 1980, dictates the number of officers as a function of the overall Army personnel strength level, but more importantly, it codifies the up-or-out promotion system (Rostker et al. 1993). The up-or-out promotion system was designed such that officers are evaluated by promotion boards and if selected, move through the ranks in cohorts, generally determined by years of service as an officer. Furthermore, any officer twice passed over for promotion to the next rank is forced to leave the service. The only exception to the separation mandate is a provision allowing for selective continuation for select officers, with the intent that it would be used sparingly. The up-or-out promotion system facilitates the rank structure shown in Figure 1, which was also set forth in DOPMA.
One of the ranks most affected by the drawdown was the rank of lieutenant colonel, which went from a promotion rate of over 91% in 2006 to a promotion rate of just 60.2% in 2016. An analysis of the promotion board results shows that the identified percentiles on evaluations are the best indicator of whether an officer was promoted. The United States Army officer performance appraisal system is a forced distribution system that uses a relative comparison of officers within a rating pool and forces raters to give top evaluations to less than 49% of their subordinates (Department of the Army Headquarters 2015). Further analysis of the promotion board results shows that seniority plays a significant role in whether or not an officer receives a top evaluation. However, the function used by raters to sort and evaluate subordinates is unknown (black-box) and noisy due to raters’ individual prioritization of seniority.
Related Literature
Previous work in manpower modeling is extensive. For the purpose of this simulation system design, we reviewed manpower planning methods, performance appraisal systems, talent management, simulation optimization, and model validation.
Bartholomew, Forbes, and McClean (1991) define manpower planning as “the attempt to match the supply of people with the jobs available for them”. Wang (2005) classifies operations research techniques applied in manpower planning into four branches: optimization models, Markov chain models, computer simulation models, and supply chain management through System Dynamics. Hall (2009) notes that existing literature on manpower planning falls under one of three main topics: dynamic programming, Markovian models, and goal programming. While the lists are neither exhaustive nor mutually exclusive, we classify existing techniques into the categories of optimization, Markov, and simulation models.
Early examples of optimization models include dynamic programming models that provide a framework for human resource decision making (Dailey 1958, Fisher and Morton 1968). A more recent dynamic programming application is that of Ozdemir (2013), providing an analytic hierarchy processing order for personnel selection. Bres et al. (1980) and Bastian et al. (2015) provide goal programming models to analyze officer strength and occupational mix over a finite time horizon. Kinstler et al. (2008) uses a Markovian model for the U.S. Navy Nursing Corps to determine the optimal number of new recruits to resolve the issue of overstaffing at lower ranks in order to meet requirements at higher ranks. While Markov models can be used as stand-alone models, they are more commonly incorporated into larger optimization models (Hall 2009, Zais 2014). Lesinski et al. (2011) and McGinnis, Kays, and Slaten (1994) are examples of simulation used for manpower modeling. The simulation construct developed by Lesinski et al. (2011) is used to determine whether the timing and duration of officer initial training supported a new Army unit readiness model. Similarly, McGinnis, Kays, and Slaten’s (1994) discrete event simulation model analyzes the feasibility of proposed personnel policies requiring a minimum amount of time in key assignments. What is germane to all of the existing methods is that they focus on meeting requirements in aggregate form. That is, the models estimate accessions and lateral entry requirements based on historical attrition, promotions, and forecasted growth. Very little attention is given to modeling the systems that identify and select the most qualified individuals to fill requirements rather than the binary measurement of whether a position is occupied or vacant.
Wardynski, Lyle, and Colarusso (2010) define U.S. Army officer talent as the intersection of individual knowledge, skills, and behaviors. Dabkowski et al. (2010) note that measuring officer talent is largely conceptual, but actual measurements are not necessary to analyze the talent retention impacts of policy. Their model uses a normally-distributed talent score to analyze the impact of multiple attrition patterns on the talent of senior leadership. Wardynski, Lyle, and Colarusso (2010) show that commissioning sources with the most stringent screening requirements produce higher performing officers in the senior ranks, adding credence to the Dabkowski et al. (2010) treatment of talent as a static, innate value.
Performance appraisal systems are known to have inherent bias and error. Examples of bias and error within performance appraisal systems are difficult to quantify, but include: raters evaluate more generously (leniency) or harshly (severity) than subordinates deserve, raters forming positive (halo) or negative (horn) opinions around a limited number of criteria, recent performance weighing heavily (recency), raters elevating subordinate rating to make themselves look better (self-serving), and rating subordinates relative to each other rather than performance standards (contrast/similarity) (Coens and Jenkins 2000, Carroll and Schneier 1982, Kozlowski, Chao, and Morrison 1998). Physicist and mathematician W. Edwards Deming adds that individual performance outcome depends on the structure of a system (Elmuti, Kathawala, and Wayland 1992). Performance appraisal outcomes are similarly dependent on the system structure. Inaccuracy within a performance appraisal system refers to the extent that the evaluation outcome differs from the true distribution of performance levels across a group of evaluated employees (Carroll and Schneier 1982).
Validating a simulation model for the purpose of estimating the inaccuracy in a performance appraisal system is a non-trivial task. Law (2015) states that “the most definitive test of a simulation model’s validity is to establish that its output data closely resemble the output data that would be expected from the actual system”. Numerous methods exist for model validation. Balci (1998) lists 75 techniques for model verification, validation, and testing, but notes that most practitioners use informal techniques that rely on human reasoning and subjectivity.
Problem Statement
Kane (2012) notes that evaluations are often tied to the position, rather than strictly on performance. This is most prevalent in branches that have key developmental positions. In order to mitigate the effect of officers’ assignments influencing the assigned rating, we use data strictly for functional area majors with homogeneity of assignments. A functional area is a “grouping of officers by technical specialty or skills other than an arm, service, or branch that usually requires unique education, training, and experience”, according to Department of the Army Headquarters (2014).
Officers receive evaluations at each assignment where they are rated relative to their peers, or officers of the same rank. Figure 2 shows the typical flow chart for a U.S. Army officer. Officers enter the evaluation system and are assigned into a group of their peers, known as a rating pool. In general, each officer is given an annual evaluation based on their performance relative to the other officers in the same rating pool. After the evaluation, the officer either remains in the same pool or is reassigned to a different pool. The reassignment typically involves a physical change in geographic location. Once an officer has spent a specified time in the system, five years in the case of Figure 1, he/she exits the system. The officer’s file is presented to a promotion board, comprised of general officers, who make the decision as to whether the officer continues to the successive rank or is forced to leave military service.
Raters are restricted from giving more than 49% of the officers in their pool a top evaluation. The intent of this forced distribution mandate is to provide a differentiation of performance for personnel management decisions. Forced distribution performance appraisal systems applied to a small number of employees create misidentification of performance. Mohrman, Resnick-West, and Lawler (1989) state that forced distribution systems should only be applied to a large enough group of individuals, specifically no less than 50 employees. The binomial distribution provides some insight when attempting to quantify this misidentification of performance. If X is a random variable denoting the number of top 49% per- forming officers within a rating pool of n officers, and officer performance is independent, then X follows Binomial(n, 0.49). Misidentification occur when the number of officers deserving top evaluations exceeds the profile constraint. For example, if n = 15, E[Misidentifications] is ∑15, x=8 P(X = x)(x − 7) = 0.9470. When n = 100, E[Misidentifications] is ∑100, x=50 P(X = x)(x − 49) = 1.9893. Therefore, if a population of 300 officers is divided into 20 rating pools, we would expect 18.9405 (0.9470 x 20) misidentifications. The same 300 officers divided into three rating pools results in 5.9680 (1.9893 x 3) expected misidentifications. Other factors that affect the accuracy of evaluations are the distribution of rating pool sizes, frequency of moves between rating pools, and human behavior within the system. These factors applied over a multi-year timeframe necessitate the use of techniques such as simulation to quantify the error induced by a forced distribution performance evaluation system.
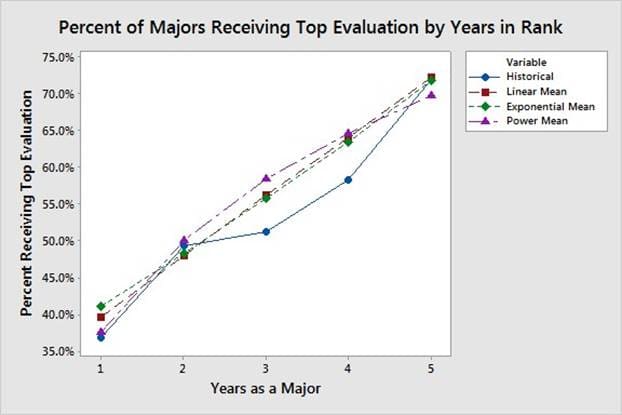
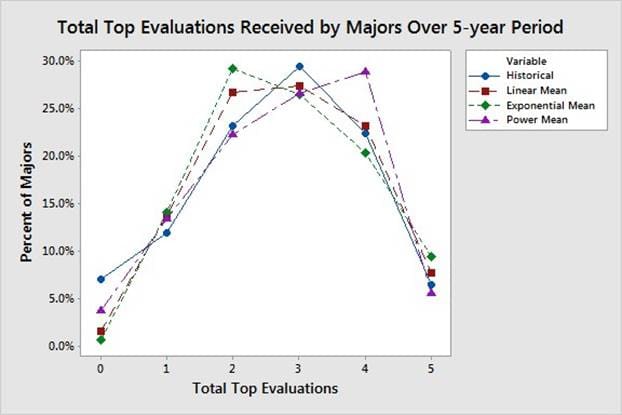
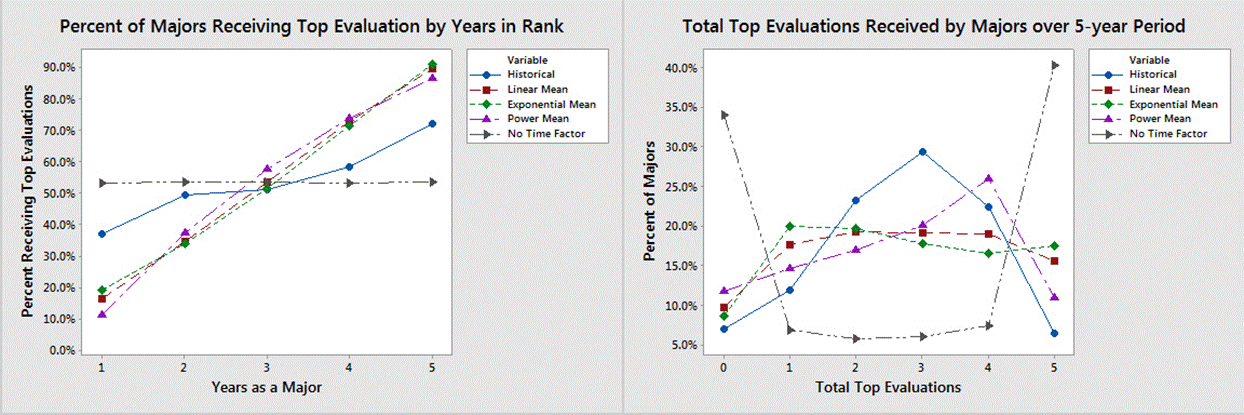
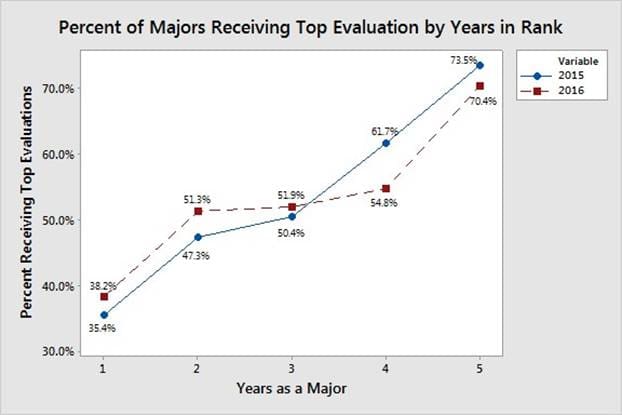
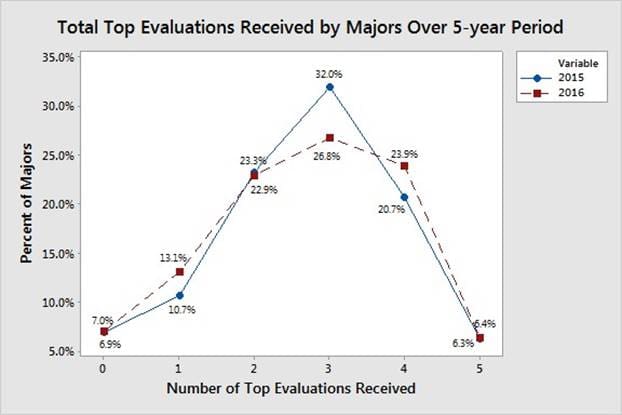
Quantifying rater behavior of ranking and evaluating subordinates requires the application of advanced model validation methods. Figure 3 shows that officers are more likely to receive a top evaluation as their time in rank increases. Figure 4 shows the distribution of the number of top evaluations that majors receive over a 5-year period. The simulation output corresponding to the distributions shown in Figure 3 and Figure 4 is subject to the rater function used to rank and evaluate subordinates within each rating pool, i.e., a black-box function. The data shown in Figure 3 and Figure 4 is from majors facing promotion boards in 2015 and 2016, which had promotion rates of 60.4% and 60.2%, respectively. The basis for model comparison is an average of these two years due to their similarity and to focus the model on current evaluation trends.
The contribution of our study is examining a method for estimating this black-box function using simulation optimization. We build a discrete event simulation model and modify the sorting function used to simulate human behavior using OptQuest and the Kim-Nelson (KN) procedure, a fully-sequential ranking and selection simulation optimization method. Parameters from multiple functions are evaluated to determine their goodness-of-fit in replicating rater behavior.
In order to evaluate the output, we use an adaptation of the cost function J(θ) Ikonen and Najim (2002) presented in the general form:

The quadratic cost function of Equation (1) assigns αk weights to the squared differences between K observed outputs, y(k), and the model predictions, θ T ϕ(k). The objective is to minimize the cost function J with respect to parameters θ as in Equation (2):
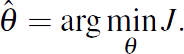
Section 4 elaborates on the derivation of the cost function and the parameters within the system.